微软自研语音基座来了:MAI-Voice-1 + MAI-Transcribe-1 与 BibiGPT 播客总结的新机会
2026 年 4 月微软发布 MAI-Voice-1(60 秒音频 1 秒生成)和 MAI-Transcribe-1 自研语音基座,对 AI 播客转录、多语言字幕和视频总结意味着什么?本文对比 Whisper / Voxtral,解读 BibiGPT 的兼容路线与自定义转录引擎。
微软自研语音基座来了:MAI-Voice-1 + MAI-Transcribe-1 与 BibiGPT 播客总结的新机会
目录
- MAI-Transcribe-1 是什么?对 AI 播客转录有什么影响?
- MAI-Voice-1:60 秒音频只要 1 秒生成
- MAI-Transcribe-1 vs Whisper / Voxtral:三个关键差异
- 对 BibiGPT 用户意味着什么:更稳的播客总结底座
- BibiGPT 如何兼容或互补 MAI 系列
- 常见问题解答(FAQ)
- 结语
MAI-Transcribe-1 是什么?对 AI 播客转录有什么影响?
核心答案: MAI-Transcribe-1 是微软 2026 年 4 月发布的自研 ASR(自动语音识别)模型,同属「MAI」自研语音基座家族,和 MAI-Voice-1(TTS)一同发布。对 AI 播客转录的直接影响是:多语言场景下的词错误率(WER)进一步降低,推理成本下降,意味着 AI 播客总结 这类下游应用可以用更低成本拿到更准的字幕底稿。
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
2026 年 4 月 2 日,微软 MAI(Microsoft AI)团队一次性公开了两款自研语音模型:
- MAI-Voice-1:语音合成(TTS),60 秒音频只需 1 秒生成,单 GPU 可运行
- MAI-Transcribe-1:语音识别(ASR),多语言场景下达到新 SOTA,推理延迟显著下降
这是微软第一次把「整条语音栈」(输入端 ASR + 输出端 TTS)都换成自研模型,而不是继续依赖 OpenAI Whisper 和第三方 TTS。对开发者和 AI 音视频工具来说,这件事的信号非常明确:语音基础模型的竞争进入"自研 + 端到端低延迟"阶段,播客、访谈、会议录音这类长音频场景将受益最明显。
MAI-Voice-1:60 秒音频只要 1 秒生成
核心答案: MAI-Voice-1 是微软自研的语音合成模型,宣称 60 秒音频在单 GPU 上只需 1 秒完成,属于当前业内最快的 TTS 之一。可用于实时语音助手、低延迟配音、长文章朗读等场景,已集成到 Copilot Daily / Podcasts 等 Microsoft 产品内。
核心亮点:
- 60 倍实时:60 秒文本→1 秒音频输出(单 GPU),对长内容配音非常友好
- 单 GPU 运行:相比很多需要多 GPU 集群的 TTS,部署门槛低
- 已在产品内上线:Copilot 的 Daily News 栏目、Podcasts 生成等场景已使用该模型
对 BibiGPT 这类「长音视频总结 → 播客化」场景的启示:输入端的播客转录和输出端的"小宇宙风格双人对谈"生成,都有条件在更低延迟下完成。BibiGPT 目前的 小宇宙播客生成 功能已经支持从视频直接生成双人对谈音频,MAI-Voice-1 这类高速 TTS 的成熟,让"边总结边配音"的实时工作流变得可行。
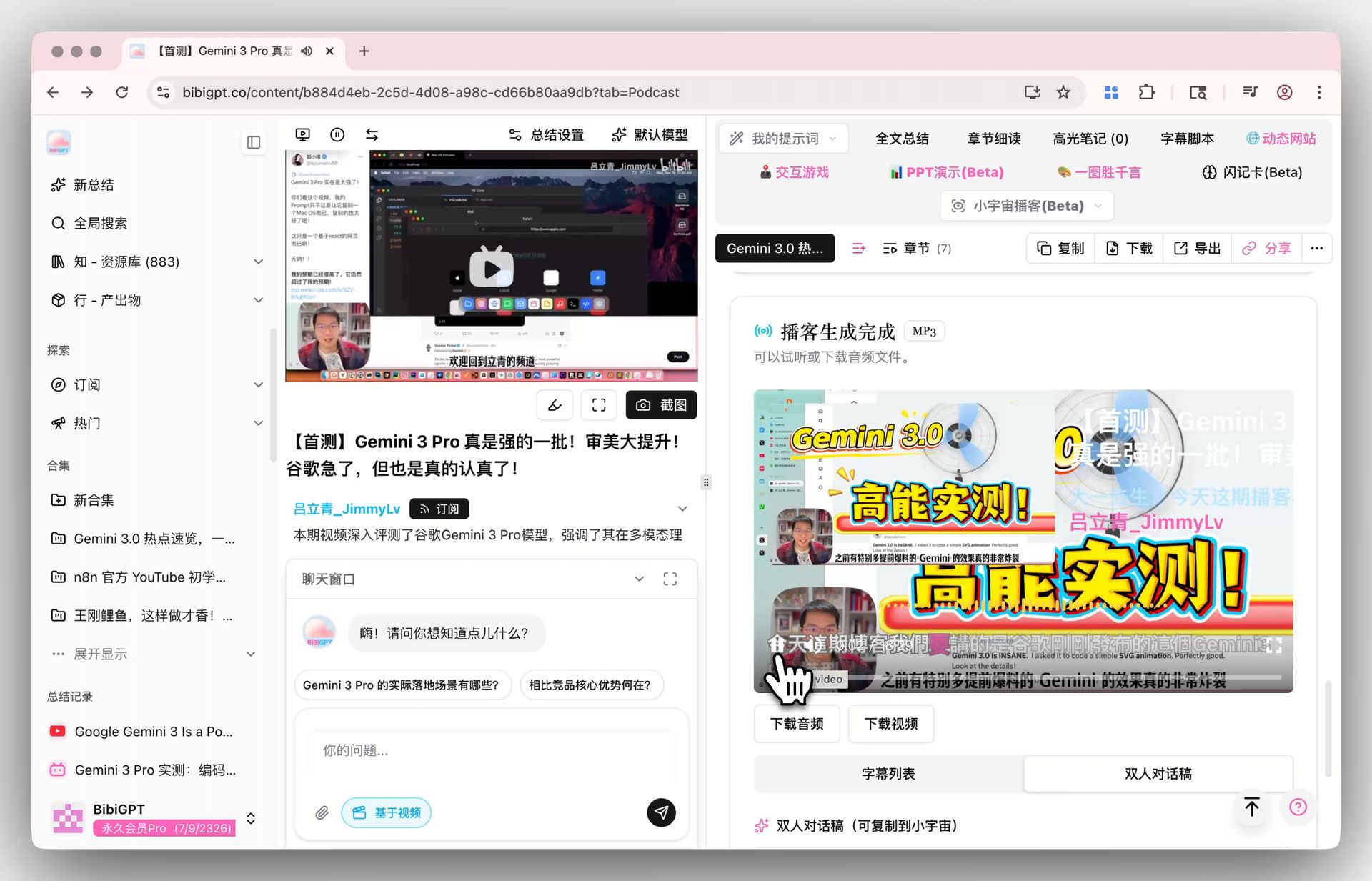 小宇宙播客生成功能截图
小宇宙播客生成功能截图
MAI-Transcribe-1 vs Whisper / Voxtral:三个关键差异
核心答案: MAI-Transcribe-1 相比 OpenAI Whisper-v3 / Mistral Voxtral,主要差异在三点:更低的 WER(尤其在嘈杂环境和专业术语)、更快的推理、更紧密的 Azure / Copilot 整合。短期看,Whisper 仍是开源生态的首选,MAI-Transcribe-1 是商用 API 的新标杆。
三款模型的差异化定位:
| 维度 | MAI-Transcribe-1 | OpenAI Whisper-v3 | Mistral Voxtral |
|---|---|---|---|
| 开源 | 否(商用 API) | 是(MIT) | 是(Apache 2.0) |
| 多语言 | 25+ 语言,中文表现稳定 | 99 语言,长尾语言弱 | 主打英 / 欧语种 |
| 长音频 | 原生 60 分钟 + 上下文 | 需分段处理 | 支持长上下文 |
| 延迟 | 显著低于 Whisper | 中等 | 快 |
| 部署 | Azure 托管为主 | 可本地 / 云部署 | 开源自部署 |
| 价格 | 按分钟计费 | 开源免费(自己算 GPU) | 开源免费 |
据 Microsoft AI 官方博客,MAI 系列的目标是把微软全栈 AI(搜索、Copilot、Office、游戏、Bing)底层的语音模型统一到自研技术上。对应用层而言,意味着更稳定的 SLA 和更透明的模型版本演进。
对于 BibiGPT 这类"不依赖单一语音模型"的产品,MAI-Transcribe-1 更像是 自定义转录引擎 池中的又一个选项,而不是替代。
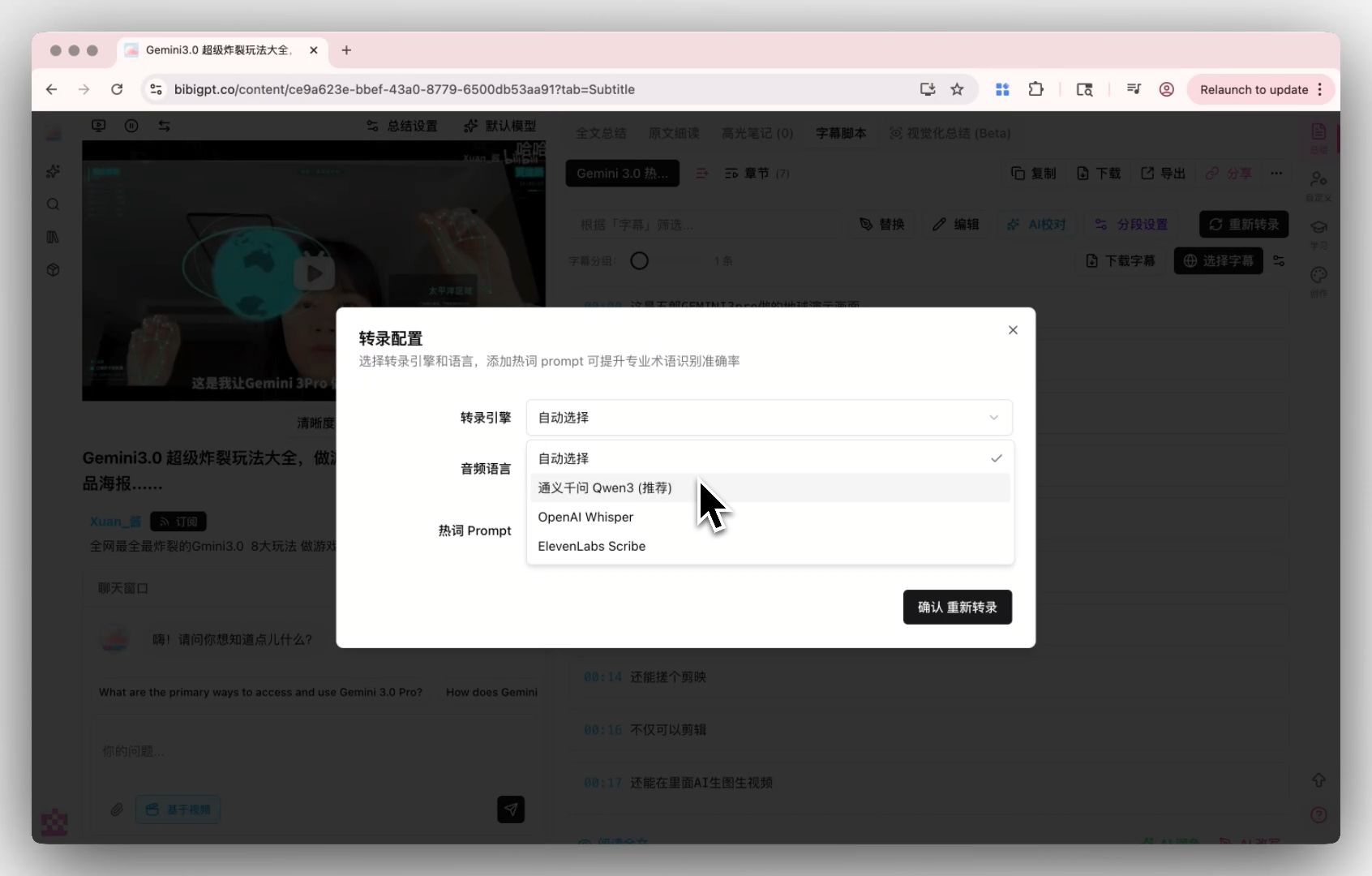 自定义转录引擎:供应商展示
自定义转录引擎:供应商展示
对 BibiGPT 用户意味着什么:更稳的播客总结底座
核心答案: 对 BibiGPT 用户而言,MAI-Transcribe-1 的发布意味着三件事:播客 / 长音频的 AI 转录更准、多语言场景下 字幕翻译工作流 更丝滑、自定义转录引擎 的可选池进一步扩展。
场景 1:播客 / 访谈类长音频
长音频(超过 30 分钟)是 Whisper 的弱项——分段容易丢失语境,而 MAI-Transcribe-1 原生支持更长上下文。对 BibiGPT 用户而言,小宇宙 / Spotify 长播客、行业访谈的转录质量会更稳。相关对比可参考 AI 播客总结工作流指南。
场景 2:多语言内容跨境整理
海外新闻、日韩访谈、英中双语会议,MAI 系列在多语言混杂场景下的 WER 表现更稳。对于做内容出海 / 跨境研究的用户,自动翻译上传 的"识别 → 翻译"链条可以用上更准的 ASR 底座。
场景 3:专业术语密集内容
医学、法律、金融、技术领域的术语密集内容,过去依赖 ElevenLabs Scribe 等专业引擎。MAI-Transcribe-1 的加入让可选池更丰富,用户可以根据内容特点选择性价比最高的底座。
BibiGPT 如何兼容或互补 MAI 系列
核心答案: BibiGPT 的定位从来不是"绑定单一语音模型",而是"把任意高质量语音基座变成用户可见的知识产物"。MAI-Voice-1 / Transcribe-1 的出现,让 BibiGPT 的核心工作流(转录 → 总结 → 思维导图 → 图文 / 播客)可以用更稳的底座运行。
兼容路线:把 MAI-Transcribe-1 接入自定义转录引擎
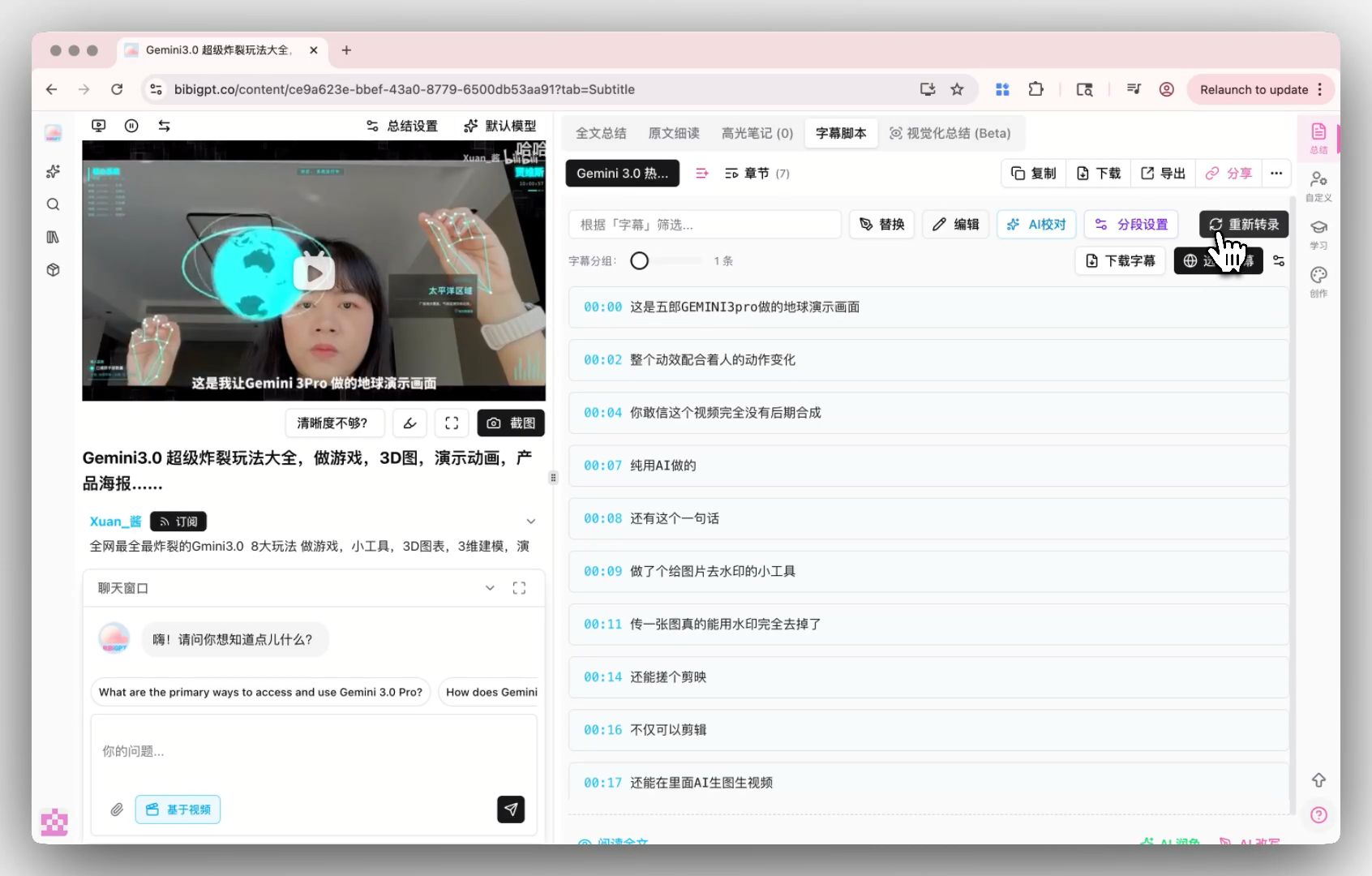 自定义转录引擎入口
自定义转录引擎入口
BibiGPT 的 自定义转录引擎 现已支持 OpenAI Whisper 与业界顶尖的 ElevenLabs Scribe。MAI-Transcribe-1 当前仅在 Azure / Copilot 内部使用,公开 API 成熟后,BibiGPT 会评估加入引擎池——让对转录精度有极致要求的用户在字幕脚本界面一键切换。
互补路线:MAI 做底座,BibiGPT 做"知识产物"加工
即使底座换成最强的 ASR,用户拿到的仍然只是一份纯文字。BibiGPT 的独特价值在字幕产出之后:
- 结构化摘要 + 思维导图:按章节拆解长音频知识
- AI 高光笔记:一键提取带时间戳的精华片段
- 合集归纳总结:多条播客跨集归纳,形成知识图谱
- 小宇宙双人播客生成:把总结反向变成播客,形成「输入播客 → 输出播客」的闭环
这种"底座可替换,上层产品力稳定"的架构,是 BibiGPT 能持续吸纳业界最新语音技术的关键。更深的背景可参考 微软 Copilot vs BibiGPT 视频总结对比 与 MAI-Transcribe-1 与 Cohere 开源 ASR 的更早一轮对比。
AI Subtitle Extraction Preview
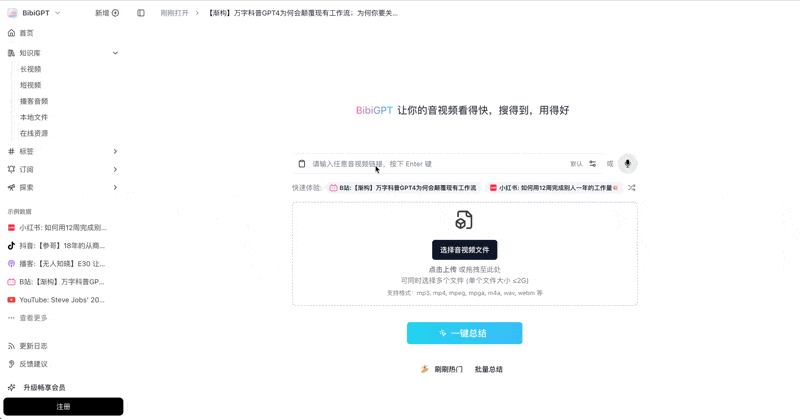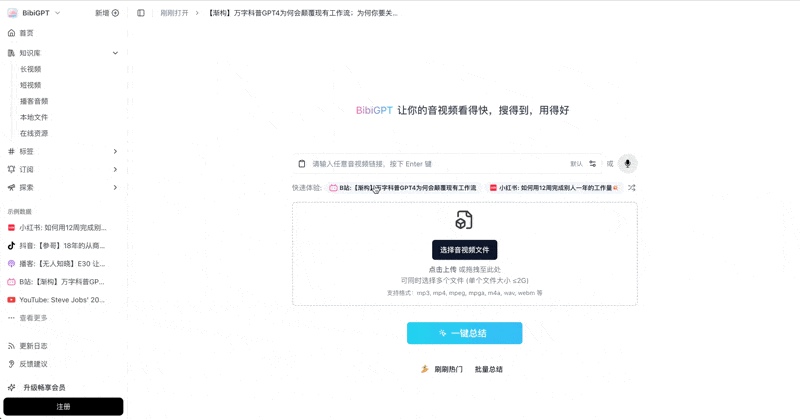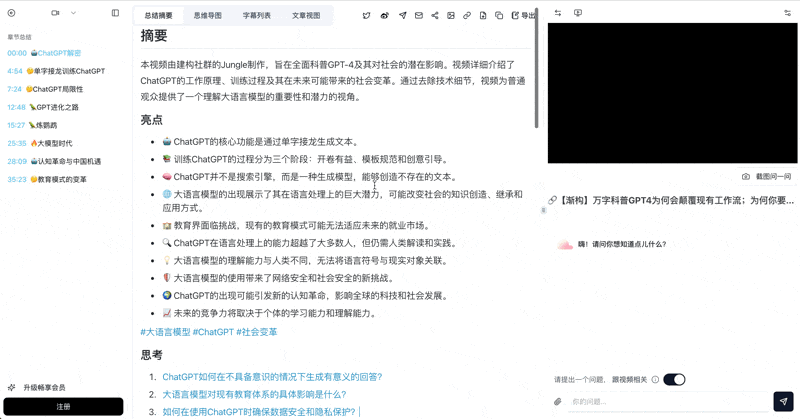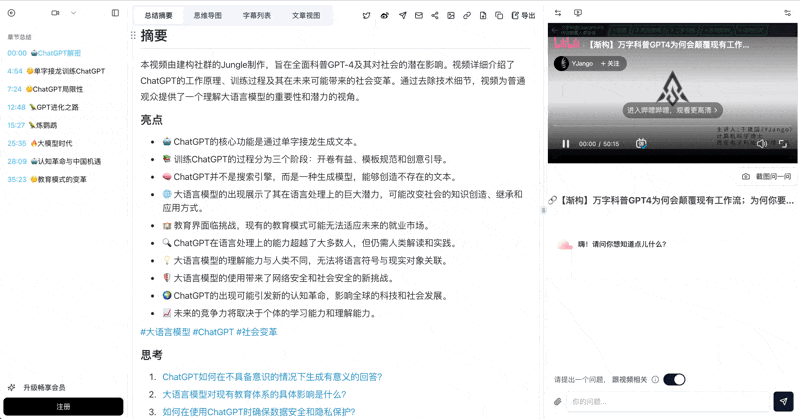
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free常见问题解答(FAQ)
Q1: MAI-Transcribe-1 是开源的吗?可以本地部署吗?
A: 目前 MAI-Transcribe-1 不是开源模型,仅通过 Azure / Copilot 产品线提供。如需本地部署,可以继续使用 OpenAI Whisper(MIT)或 Mistral Voxtral(Apache 2.0)。
Q2: BibiGPT 现在默认使用的是 MAI-Transcribe-1 吗?
A: 目前 BibiGPT 默认使用自研 + Whisper 混合管线,用户可在 自定义转录引擎 中切换到 ElevenLabs Scribe。MAI-Transcribe-1 公开 API 成熟后会评估加入。
Q3: MAI-Voice-1 对播客创作者有什么直接用处?
A: 创作者未来可以用 MAI-Voice-1 类高速 TTS 把文字稿反向变成多主播音频。BibiGPT 的 小宇宙播客生成 已支持从视频生成双人对谈,底层 TTS 的进步会直接让该功能延迟更低。
Q4: 如果只看中文播客,MAI-Transcribe-1 比 Whisper 强多少?
A: 目前公开的 benchmark 中文语料有限,建议在 BibiGPT 上同时跑 Whisper 与 ElevenLabs Scribe 作对比。等 MAI-Transcribe-1 公开 API 后再做实测对比(BibiGPT 会补上评测博文)。
Q5: 为什么不直接把所有转录都切到最强模型?
A: 不同模型各有成本 / 精度 / 语言支持的取舍,强绑定单一模型会让用户在极端场景(如小语种、专业术语)失去选择权。BibiGPT 的 自定义转录引擎 让这件事回到用户手里。
结语
微软 MAI-Voice-1 + MAI-Transcribe-1 的发布,标志着大厂语音基座进入"自研 + 端到端低延迟"阶段。对 AI 音视频工具而言,这是一次底层能力的整体升级——转录更准、合成更快、长音频更稳。
BibiGPT 的产品哲学从来不是绑定某一款模型,而是让任何优秀的底座都能无缝变成用户可见的知识产物。MAI 系列成熟之时,BibiGPT 会第一时间把它加入 自定义转录引擎 的可选池,继续为中文播客、跨境视频、长音频学习场景提供最稳的 AI 总结体验。
立即访问BibiGPT官网,开启你的AI高效学习之旅:
- 🌐 官网: https://bibigpt.co
- 📱 移动端下载: https://bibigpt.co/app
- 💻 桌面端下载: https://bibigpt.co/download/desktop
- ✨ 了解更多功能: https://bibigpt.co/features
BibiGPT 团队