Qwen3.5 Omni 长视频总结实测:10 小时音频 + 400 秒视频原生处理 vs BibiGPT(2026)
阿里 Qwen3.5 Omni 原生支持 10+ 小时音频和 400+ 秒 720p 视频处理、113 语言识别、256k 上下文——这是 AI 音视频总结的新天花板吗?本文实测模型能力并对比 BibiGPT 的用户端体验差异。
Qwen3.5 Omni 长视频总结实测:10 小时音频 + 400 秒视频原生处理 vs BibiGPT(2026)
目录
- Qwen3.5 Omni 对 AI 视频总结意味着什么?
- Qwen3.5 Omni 的技术规格速读
- 从「模型能力」到「终端体验」还有多远?
- BibiGPT × 开源多模态模型:用户端的 AI 视频总结实践
- 差异化优势:BibiGPT 为什么仍然值得用
- 常见问题解答(FAQ)
- 结语
Qwen3.5 Omni 对 AI 视频总结意味着什么?
核心答案: 阿里通义于 2026 年 3 月 30 日发布的 Qwen3.5 Omni 是目前全模态能力最强的开源模型之一,原生支持 10+ 小时音频、400+ 秒 720p 视频、113 种语言识别、256k 长上下文,把 AI 视频总结的"模型上限"直接抬到了云端闭源模型的水准。对终端用户而言,它更像是底层引擎层的一次升级——开源模型路线给 BibiGPT 这类 AI 音视频助理提供了更多可选底座,让产品能用更低成本提供更长、更准、更多语言的总结服务。
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
如果你过去一年抱怨过"视频太长 AI 跑不完""非英文视频转录错字率高""总结只能看前 30 分钟就断"——Qwen3.5 Omni 这一代全模态模型,就是在直接解决你遇到的这些瓶颈。本文从三个视角拆开它:模型规格、跑通它需要什么、它如何通过 BibiGPT 这类产品落地到你手上。
Qwen3.5 Omni 的技术规格速读
核心答案: Qwen3.5 Omni 的核心卖点是"一个模型跨越文本/图像/音频/视频四种模态",实测规格包括 10+ 小时音频原生输入、400+ 秒 720p 视频帧理解、256k tokens 长上下文、113 种语言 ASR 识别,并沿用了 Qwen 系列的 Thinker/Talker 双脑架构。
基于阿里通义官方 GitHub 和 Hugging Face 社区的公开发布(见 阿里通义 Qwen 团队发布说明),Qwen3.5 Omni 的关键能力如下:
| 维度 | 规格 | 对 AI 视频总结的意义 |
|---|---|---|
| 音频处理上限 | 10+ 小时原生输入 | 完整覆盖超长播客、研讨会、全天讲座 |
| 视频处理上限 | 400+ 秒 720p 帧理解 | 支持画面内容分析+语音识别的长镜头总结 |
| 语言覆盖 | 113 种语言 ASR | 多语言内容本地化、跨国团队会议 |
| 上下文长度 | 256k tokens | 超长视频+引用文献+交叉提问可一次容纳 |
| 架构 | Thinker / Talker 双脑 | 推理路径和语音输出分离,实时交互更自然 |
| 许可证 | Apache 2.0(开源) | 可商用、可微调、可本地化部署 |
如果你想对比几代旗舰开源模型的能力边界,可以翻一下 2026 年 AI 音视频总结工具最佳评测,里面收录了 GPT、Claude、Gemini、Qwen 系列在相同视频上的对照数据。
开源路线的真正价值
Qwen3.5 Omni 发布的那一周,InfiniteTalk AI、Gemma 4、Llama 4 Scout、Microsoft MAI 也相继放出新模型,开源多模态赛道已进入"每月一代"的节奏。对用户来说这意味着:
- 长视频总结不再是付费特权:开源底座让产品方可以降低定价
- 非英文视频终于有救:113 语言覆盖把西班牙语播客、日文讲座、韩语直播都拉进可用范围
- 隐私敏感场景多了选项:Apache 2.0 允许本地化部署,企业视频不用再外传云端
从「模型能力」到「终端体验」还有多远?
核心答案: 模型规格只是天花板,终端体验还取决于工程化、平台适配、交互设计和稳定性。Qwen3.5 Omni 的 256k 上下文在论文里很美,但你要从 B 站链接到最终总结文本,中间还隔着 URL 解析、字幕抓取、硬字幕 OCR、分段预处理、Prompt 工程、长文渲染、导出链路。
一个合格的 AI 音视频助理至少要解决以下 7 个工程问题:
- URL 解析:YouTube / B 站 / 抖音 / 小红书 / 播客 30+ 平台的链接格式和反爬策略都不同
- 字幕源适配:有 CC 的直接抓,没 CC 的走 ASR,硬字幕要跑 OCR
- 超长内容切片:256k 听起来大,10 小时音频塞进去也会触顶,需要智能切片 + 摘要 merge
- 多语言翻译:字幕逐行翻译要保留时间戳,不能整段丢给模型
- 结构化输出:章节 / 时间戳 / 摘要 / 思维导图 / 重点高亮,需要稳定的 Prompt 工程
- 导出兼容:SRT / Markdown / PDF / 公众号图文 / Notion 格式各有规范
- 稳定性和成本:跑一次 10 小时播客模型成本可观,产品侧要做缓存、队列、优先级
这就是为什么光有最强的底层模型还不够——用户要的不是"Qwen3.5 Omni 原始权重",而是一个粘贴链接就能用的产品。
BibiGPT × 开源多模态模型:用户端的 AI 视频总结实践
核心答案: BibiGPT 作为国内 Top 1 的 AI 音视频助理,已服务超过 100 万用户,累计生成超过 500 万次 AI 总结。面对 Qwen3.5 Omni 这类新底座的发布,BibiGPT 的定位是"把开源模型的能力封装成终端用户的一键体验",让用户不需要关心模型名称、部署环境、切片策略,只负责粘贴链接。
一键体验:从 URL 到结构化总结
See BibiGPT's AI Summary in Action
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free用 BibiGPT 总结一个 3 小时的 B 站技术分享的流程:
- 打开 bibigpt.co 粘贴链接
- 系统自动抓取字幕(有 CC 直接用,没 CC 调 AI 转录)
- 智能切片 + 分段总结 + 章节合并
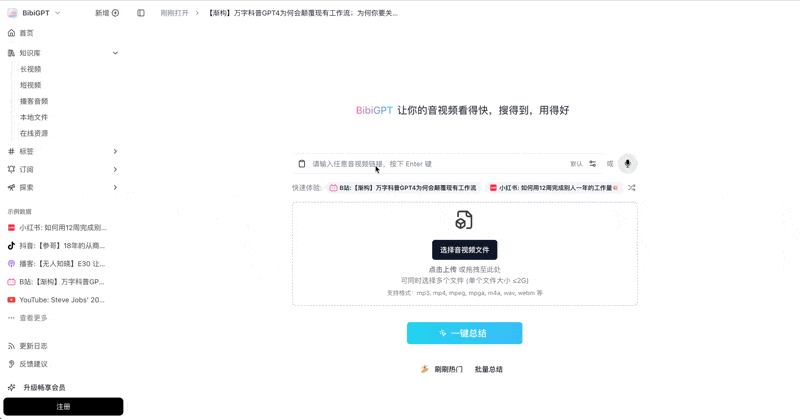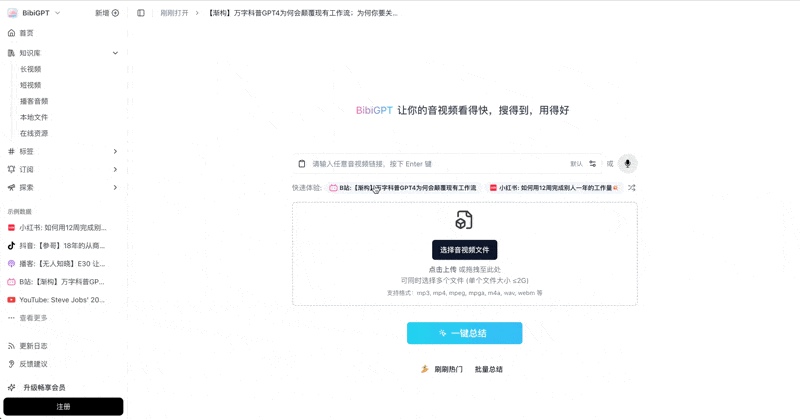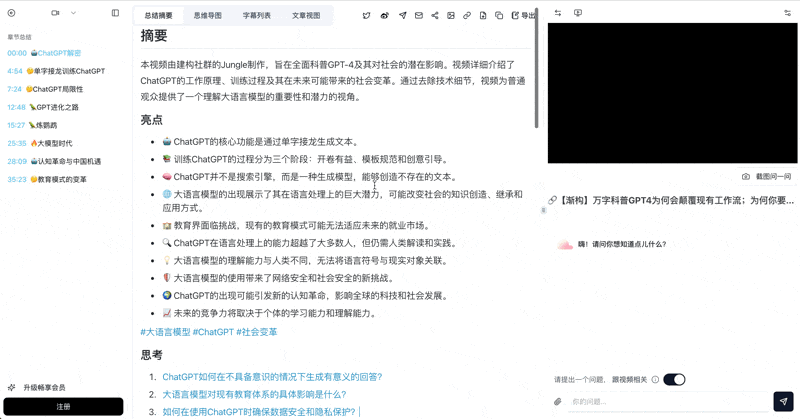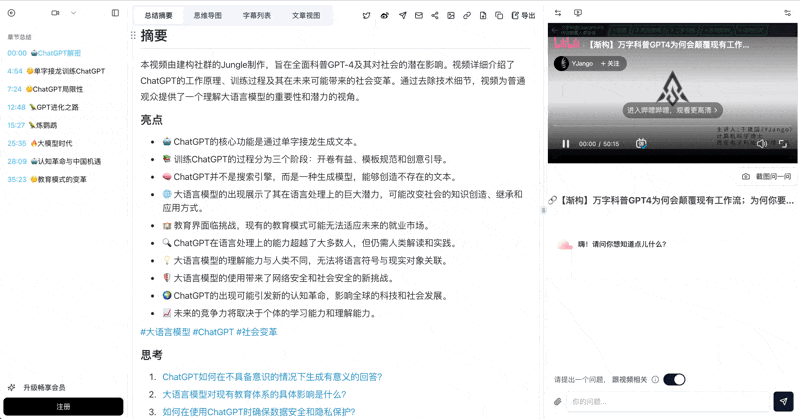
- 约 2 分钟后拿到:完整字幕、章节摘要、思维导图、AI 可对话视频问答
同样的流程跨平台复用,B 站视频总结、YouTube 视频总结、小宇宙播客总结 都是同一条链路。
长视频场景的关键工程
超长音视频是 Qwen3.5 Omni 这代模型的强项,但终端用户真正体验到"总结 4 小时播客毫无断点"需要的不只是模型长上下文,还有:
- 智能字幕分段:自动把 174 条零碎字幕合并为 38 条通顺长句,减少上下文浪费
- 章节细读:把章节摘要、AI 润色和字幕整合到专注阅读选项卡
- AI 视频对话:任何疑问直接问视频,带时间戳来源追溯
- 视觉化分析:画面关键帧截图 + 内容分析,生成公众号图文、小红书配图、短视频
 AI 视频转文章生成界面
AI 视频转文章生成界面
差异化优势:BibiGPT 为什么仍然值得用
核心答案: Qwen3.5 Omni 是模型底座,BibiGPT 是产品体验——两者不是替代关系,而是互相成就。BibiGPT 的差异化在四个层面:30+ 平台覆盖、字幕链路完整、中文创作场景深耕、与 Notion/Obsidian 生态联动。
1. 30+ 平台覆盖 + 反爬工程
开源模型解决不了 B 站、小红书、抖音等国内平台的抓取问题。BibiGPT 持续投入在平台适配上,支持 30+ 主流音视频平台,这是"你拿 Qwen3.5 Omni 权重自己跑"无法复现的工程价值。
2. 字幕链路完整
从提取、翻译、分段、导出到硬字幕 OCR 的全链路闭环。不只是"给我一份总结",而是"给我字幕 + 总结 + 翻译 + SRT 导出 + AI 改写"一次完成。相比单纯的模型调用,产品化链路减少了 5-8 次手动操作。
3. 中文创作场景深耕
公众号图文改写、小红书宣传图、短视频生成——这些是中文创作者的高频需求,开源模型本身不解决"导出到公众号"这种业务侧问题。BibiGPT 的 AI 视频转文章 直接面向内容创作者的二次分发场景。
4. 笔记工具深度联动
Notion、Obsidian、Readwise、Cubox——BibiGPT 内置了多条笔记同步链路。用户粘贴一个视频链接,总结结果可以直接落到自己的知识库里,这是原始模型调用做不到的生态价值。
常见问题解答(FAQ)
Q1:Qwen3.5 Omni 比 GPT-5 或 Gemini 3 更强吗? A:在"开源全模态"这个细分赛道,Qwen3.5 Omni 是目前最强的选择之一,原生 10 小时音频处理和 113 语言覆盖都在云端闭源模型的水准上。在闭源模型之间的横评可以看 NotebookLM vs BibiGPT AI 视频总结对比。
Q2:我可以用 Qwen3.5 Omni 自己跑视频总结吗? A:可以。Apache 2.0 许可证允许商用和本地部署。但你需要解决 GPU 成本、URL 解析、字幕抓取、长视频切片、结构化输出这一整套工程问题。如果没有这些工程能力,直接用封装好的产品如 BibiGPT 性价比更高。
Q3:BibiGPT 用的就是 Qwen3.5 Omni 吗? A:BibiGPT 的模型选型是动态的,会根据场景和成本在多个模型间切换。核心原则是"给用户最稳、最准、最快的体验",具体底座对终端用户透明。
Q4:10 小时音频真的能一次跑完吗? A:模型规格上支持,但实际体验取决于具体实现。BibiGPT 通过智能切片 + 分段总结 + merge 策略,实测 3-5 小时的播客可以稳定在 2-3 分钟内产出完整结构化总结,10 小时超长内容建议分段上传。
Q5:开源模型会让 BibiGPT 这类产品被取代吗? A:相反——开源模型越强,产品化链路的价值越被凸显。大多数用户要的不是模型权重,而是粘贴链接就能用的体验。模型能力提升会让 BibiGPT 变得更快、更准、更便宜,而不是被替代。
结语
Qwen3.5 Omni 代表的开源多模态浪潮正在把"AI 视频总结"这件事从奢侈品变成日用品。模型能力的天花板越抬越高,但对终端用户来说,"粘贴一个链接就能用"的产品体验仍然是决定日常是否使用的关键变量。
如果你是内容研究者、自媒体创作者、学生或职场人士,最划算的选择不是追着开源模型跑权重,而是用好已经封装好的 AI 音视频助理:
- 🎬 访问 bibigpt.co 粘贴任意视频链接
- 🌐 海外用户可以使用 aitodo.co
- 💬 需要批量 API 接入?参考 BibiGPT Agent 技能 介绍
BibiGPT 团队